![AIで、しごとするなら 活用・開発・導入を加速させる[AI専門メディア]](https://tech.axell.co.jp/wp-content/themes/axell-tech-2026/assets/images/main_copy.png)



今回は、前回紹介した動画のオブジェクト検出(https://interface.cqpub.co.jp/ailia014/)に続き、YOLO11-segが対応する複数モデルを用いた静止画入力でのオブジェクト検出を取り上げます。
使用するモデルと特徴
検証対象としたのは、
- YOLO11n-seg
- YOLO11s-seg
- YOLO11m-seg
- YOLO11l-seg
- YOLO11x-seg
の計5種類です。それぞれのモデルの特徴と主な用途を表1にまとめました。
| モデル | 特徴 | 主な用途の目安 |
|---|---|---|
| YOLO11n-seg (Nano) | 最小/最速.パラメータ数が非常に少なく軽量で精度は低め | モバイル端末,ラズベリー・パイ,リアルタイム監視 |
| YOLO11s-seg (Small) | 小型で高速.Nanoより精度が高いが依然軽量 | 組み込み機器,ドローン,IoTカメラ |
| YOLO11m-seg (Medium) | バランス型で速度と精度を両立 | 一般的な画像解析アプリ,エッジAI |
| YOLO11l-seg (Large) | 精度重視.計算コストは増えるがより正確 | 研究用途,クラウド推論,業務システム |
| YOLO11x-seg (Extra Large) | 最大規模で最高精度.GPUリソース必須,リアルタイム性は劣る | 高精度要求のある産業応用,サーバ推論 |
今回は静止画による検出結果を比較しますが、処理速度(FPSなど)については、同一モデルを用いた動画入力でのオブジェクト検出を次回で紹介する予定です。
なお、環境構築方法などの詳細はここでは扱いません。実行環境のセットアップ手順や基本的な使い方、静止画での動作確認方法については、前回の記事を参照してください。
モデルごとの精度や挙動を検証
検証に使用した静止画
今回は、前回の検証と同じ画像を使用し、モデルごとの検出精度や挙動を比較しました。画像の概要は次の通りです。
- イベント風景(1716×1029):多数の人物が写っており、人の検出性能を確認するために利用。
- 新幹線ホーム風景(4032×2268):ホームにいる人物と新幹線を区別して検出可能かを確認。
- 複数オブジェクト・リスト(1024×1536):生成AIで作成した画像で、多様な物体が含まれている。検出対象が正しく識別されるかを検証。
検証結果1:イベント風景
オブジェクト検出結果を図1に示します。

イベント風景に対する各モデルの検出結果を表2に示します。
| オブジェクト | YOLO11n | YOLO11s | YOLO11m | YOLO11l | YOLO11x |
|---|---|---|---|---|---|
| Person | 12 | 12 | 17 | 14 | 11 |
| Backpack | 1 | 2 | 2 | 4 | 3 |
| Bicycle | 1 | ―― | 1 | ―― | ―― |
| Handbag | ―― | 1 | 4 | 3 | 3 |
| Frisbee | ―― | 2 | 1 | 3 | ―― |
| 合計 | 14 | 17 | 25 | 24 | 17 |
人の検出数が最も多かったのはYOLO11mであり、シーン全体を捉える性能が比較的高いことが分かります。また、人以外の小物類(バッグやフリスビーなど)の検出数が多かったのはYOLO11で、精度重視モデルの強みが表れています。ただし、検出されたフリスビーの一部はポールの誤認であり、必ずしも正確とはいえません。一方で、YOLO11xはpersonの検出数が少なめでしたが、ポールをフリスビーと誤認するケースは発生せず、対象物の誤認識が抑えられていました。
総合すると、YOLO11mは人検出に強く、YOLO11xは小物検出に優れるという傾向が確認できました。
検証結果2:新幹線ホーム風景
オブジェクト検出結果を図2に示します。
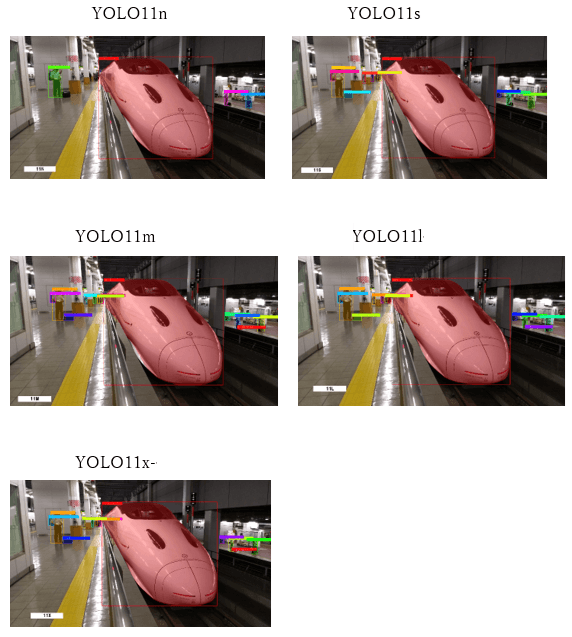
新幹線ホーム風景に対する各モデルの検出結果を表3に示します。
| オブジェクト | YOLO11n | YOLO11s | YOLO11m | YOLO11l | YOLO11x |
|---|---|---|---|---|---|
| train | 1 | 1 | 1 | 1 | 1 |
| person | 3 | 7 | 9 | 8 | 8 |
| suitcase | ―― | 1 | 2 | 2 | 2 |
| backpack | ―― | 1 | 1 | 1 | 1 |
| 合計 | 4 | 10 | 13 | 12 | 12 |
最も多くのオブジェクトを検出したのはYOLO11mで、合計13件を認識しました。軽量モデルのYOLO11nでは近距離の人物しか検出できず、遠方の人物や小物の認識は困難でした。一方、YOLO11s以降のモデルでは、遠方の人物やスーツケース、バックパックといった小物も捉えられており、モデル規模の拡大に伴って対象の識別能力が向上していることが分かります。
総合すると、YOLO11s以上のモデルでは実用的に十分な検出が可能であり、軽量モデルとの差が明確に現れる結果となりました。
検証結果3:複数オブジェクト・リスト(生成AI作成)
オブジェクト検出結果を図3に示します。

複数オブジェクト・リストに対する各モデルの検出結果を表4に示します。
| オブジェクト | YOLO11n | YOLO11s | YOLO11m | YOLO11l | YOLO11x |
|---|---|---|---|---|---|
| airplane | 1 | 1 | 1 | 1 | 1 |
| backpack | 1 | ―― | 1 | 1 | 1 |
| Bench | 1 | 1 | 1 | 1 | 1 |
| Car | 1 | 2 | 1 | 2 | 3 |
| Cat | 誤認(dog) | 1 | 1 | 1 | 1 |
| Chair | 2 | 1 | 1 | 1 | 1 |
| couch | 3 | 3 | 3 | 2 | 3 |
| cow | 1 | 1 | 1 | 1 | 1 |
| dog | 1 | 1 | 1 | 1 | 1 |
| fire hydrant | 1 | 1 | 1 | 1 | 1 |
| frisbee | ―― | 1 | 1 | 1 | 1 |
| handbag | ―― | 1 | 1 | 1 | 1 |
| motorcycle | 1 | 1 | 1 | 1 | 1 |
| parking meter | 1 | 1 | 1 | 1 | 1 |
| person | 3 | 3 | 3 | 3 | 3 |
| sheep | 1 | 1 | 1 | 1 | 1 |
| snowboard | 1 | 2 | 1 | 1 | 1 |
| stop sign | 1 | 1 | 1 | 1 | 1 |
| suitcase | ―― | 2 | 1 | 1 | 1 |
| tie | 1 | 1 | 1 | 1 | 1 |
| train | 1 | 1 | 1 | 1 | 1 |
| tv | 1 | 1 | 1 | 1 | 1 |
| zebra | 1 | 1 | 1 | 1 | 1 |
(各オブジェクト検出数のみ掲載、詳細は誤記の考察を参照)
まず、YOLO11nはfrisbee、handbag、suitcaseを検出できず、さらにcatをdogと誤認しました。軽量モデルの限界が表れています。次にYOLO11sは、backpackを検出できませんでしたが、parking meterの背後にあるcarを捉えていま。handbagとsuitcaseを同時に検出し、handbagの方を高確率で識別しました。また、snowboardを2重に検出しています。
YOLO11m/YOLO11l/YOLO11xについては、全てのオブジェクトをほぼ正しく検出しました。特にYOLO11lとYOLO11xは、背景に隠れたcarまで認識できており、より高精度な検出が確認されました。
なお、今回の検証用の画像ではソファーとイスの区別が難しいため、いずれも正解として扱っています。
まとめ
今回の検証では、YOLO11n-segからYOLO11x-segまでの5種類のモデルを用い、静止画入力でのオブジェクト検出性能を比較しました。各シナリオにおける特徴を整理すると、次の傾向が確認できました。
軽量モデル(YOLO11n/YOLO11s)
YOLO11nは最小構成で動作が軽い一方、検出数や精度は限定的でした。近距離の人物や単純な物体検出には対応可能ですが、誤認や未検出が目立ちます。
YOLO11sでは、YOLO11nよりも検出対象が増え、遠方の人物や一部の小物も捉えられるようになりました。ただし、backpackの未検出やsnowboardの2重検出など、安定性にはやや課題が残ります。
バランス型モデル(YOLO11m)
YOLO11mは、人物検出数が最も多く、イベント風景や新幹線ホームのように人が多く写る場面で特に優れた性能を発揮しました。精度と速度のバランスが良く、エッジAIや一般的な画像解析アプリにおける標準モデルとして有力です。
精度重視モデル(YOLO11l/YOLO11x)
YOLO11lは、小物類の検出に優れ、バッグやスーツケース、背景に隠れた車などをより高精度に捉える傾向がありました。誤認も少なく、安定性が高い結果となりました。
YOLO11xは、最大規模のモデルで、YOLO11lと同じように高精度な検出を行いました。特に複雑なシーンや背景に隠れた対象を識別する際に強みを発揮し、精度最優先の利用シーンに適しています。
モデル選択の目安
今回の検証結果から、YOLO11 Segmentationを利用する上での選定の指針は次の通りです。
- YOLO11m:汎用性とバランスを重視する。人物検出性能に優れたバランス型モデル。
- YOLO11l/YOLO11x:精度最優先で利用できる環境。小物検出や安定性に優れた高性能モデル。
- YOLO11n/YOLO11s:軽量/高速を重視する場合で組み込み用途やリソース制約のある環境に適した軽量モデル。
今後の展開
今回は静止画での検出性能を中心に比較しましたが、次回は動画入力に適用した際の処理速度やリアルタイム性を検証し、用途ごとの最適な選択をさらに掘り下げていきます。
氏森 充(うじもり・たかし)氏
約30年間、株式会社構造計画研究所にてIoT、ビッグデータ、機械学習、AI関連のシステム開発や実務応用に従事。退職後はLLM(大規模言語モデル)関連の情報収集や技術動向の調査・発信に注力し、雑誌『Interface』でもLLM技術に関する記事を執筆中。
SHARE THIS ARTICLE












