![AIで、しごとするなら 活用・開発・導入を加速させる[AI専門メディア]](https://tech.axell.co.jp/wp-content/themes/axell-tech-2026/assets/images/main_copy.png)



※本企画は雑誌『Interface』のWebサイトに掲載された記事を再編集したものです。
※本記事はアイリアの製品およびサービスを紹介するPR記事です。
今回は、アイリア株式会社が提供する自然言語クエリによるオープン・ドメイン音源分離モデルAudioSepを、アイリアSDK上で動作させるチュートリアルAudioSep(※注1)を紹介します。AudioSepは、thunder(雷)やwater droplets(水滴)といったテキストによるプロンプト(条件指定)を与えることで、混在した音源の中から該当する音だけを抽出できるモデルです。
(※注1)フォルダ:ailia-models/audio_processing/audiosep
https://github.com/axinc-ai/ailia-models/tree/master/audio_processing/audiosep
実行環境
今回使用した環境を表1に示します。
| 名称 | 内容 |
|---|---|
| OS | Windows 11 Pro |
| CPU | インテル® プロセッサ N100 |
| RAM | 16GB |
| Python | python-3.10.11-amd64 (3.11以上だとSRCの変更が必要になる) |
| ailia-SDK | Version 1.5.0.0 |
| ailia-models | v1.4.0(https://github.com/axinc-ai/ailia-models) |
今回の実行環境の構築手順をリスト1に示します。
> python –version
Python 3.10.11
> git clone https://github.com/axinc-ai/ailia-models.git
> cd ailia-models
> python -m venv .venv <―― Pythonの仮想環境 作成
> .venv\Scripts\activate <―― 仮想環境 で作業してください
> python -m pip install –upgrade pip
> pip install setuptools wheel
# matplotlib、scikit-image、pillow に関しては依存するバージョンがあります
> pip install matplotlib==3.8
> pip install “scikit-image<0.20” “pillow<10”
> pip install -r requirements.txt
> pip install librosa <―― audiosep 用に追加するモジュール(リスト1)環境構築の手順
音源分離を試す
1、雷と水滴の音が混在する音声からの分離
今回は、雷と水滴の音が同時に含まれる音声ファイルinput.wavを使用しプロンプトに thunderを与えた際の動作を確認しました。AudioSepを初めて実行する際には、必要な各種モデル・ファイルが自動的にインターネットからダウンロードされます。ダウンロードされたモデルはローカル環境に保存されるため、2回目以降の実行では再ダウンロードの必要はなく、保存済みのモデルが自動的に利用されます。なお、初回実行時は回線状況によって時間がかかる場合があるのでご注意ください。
実行ログをリスト2に示します(実行メッセージは、見やすいように一部編集しています)。
(.venv) PS > python audiosep.py -p “thunder” -i input.wav -s output_thunder.wav
INFO arg_utils.py (13) : Start!
INFO arg_utils.py (163) : env_id: 5
INFO arg_utils.py (166) : VulkanDNN-Intel(R) UHD Graphics (FP16)
INFO model_utils.py (74) : Downloading onnx file… (save path: audiosep_text.onnx)
INFO model_utils.py (80) : ======================= 100.00% ( 489681KB )]
INFO model_utils.py (82) : Downloading prototxt file… (save path: audiosep_text.onnx.prototxt)
INFO model_utils.py (88) : ======================= 100.00% ( 312KB )]
INFO model_utils.py (89) : ONNX file and Prototxt file are prepared!
INFO model_utils.py (74) : Downloading onnx file… (save path: audiosep_resunet.onnx)
INFO model_utils.py (80) : ======================= 100.00% ( 100179KB )]
INFO model_utils.py (82) : Downloading prototxt file… (save path: audiosep_resunet.onnx.prototxt)
INFO model_utils.py (88) : ======================= 100.00% ( 126KB )]
INFO model_utils.py (89) : ONNX file and Prototxt file are prepared!
INFO license.py (81) : ailiaへようこそ。ailia SDKは商用ライブラリです。特定の条件下では、無償使用いただけますが、原則として有償ソフトウェアです。詳細は https://ailia.ai/license/ を参照してください。
INFO audiosep.py (224) : input_text: thunder
INFO audiosep.py (227) : inference has started…
INFO audiosep.py (253) : Separated audio has been saved to output_thunder.wav
INFO audiosep.py (255) : Script finished successfully.
(.venv) PS >(リスト2)実行ログ
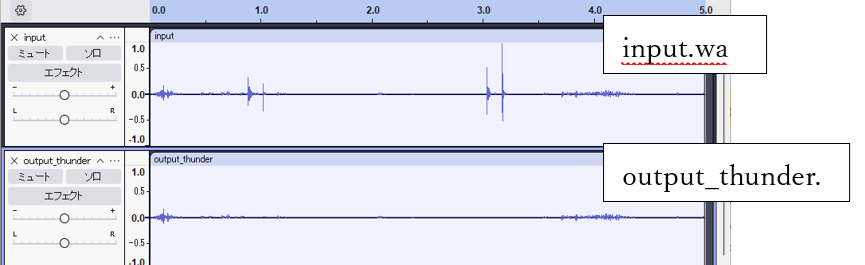
続いて、音源分離結果について述べます。プロンプトとしてthunderを指定して実行したところ、雷の音だけが抽出されていることを確認できました(図1)。
結果の検証には、次の2つの方法を用いました。
- 音の再生による聴感上の確認:出力された音声には雷音のみが含まれており、水滴音は除去された。
- Audacityによる波形表示の比較:元の音源と抽出後の音源を波形で比較することで、雷音の波形のみが抽出されていることを視覚的に確認した。なお、今回使用したテスト音源では雷の音が小さく記録されていたため、抽出後の波形も全体的に振幅が小さくなっています。
2、自作音源による音声分離の検証
次は提供されているサンプル・データではなく、自前で作成した音源を使用し、AudioSepによる音声の個別抽出が可能かどうかを検証しました。音声素材として、Springinが提供する無料のBGM/効果音素材から次の2種類の動物の鳴き声を使用しました。
- 猫の鳴き声:ネコ1.mp3
- 犬の鳴き声:イヌ1.mp3
これらの音声ファイルを、音声編集ツールAudacityを用いて1つの音源に合成し、猫と犬の鳴き声が混在する状態の入力音声を作成しました。
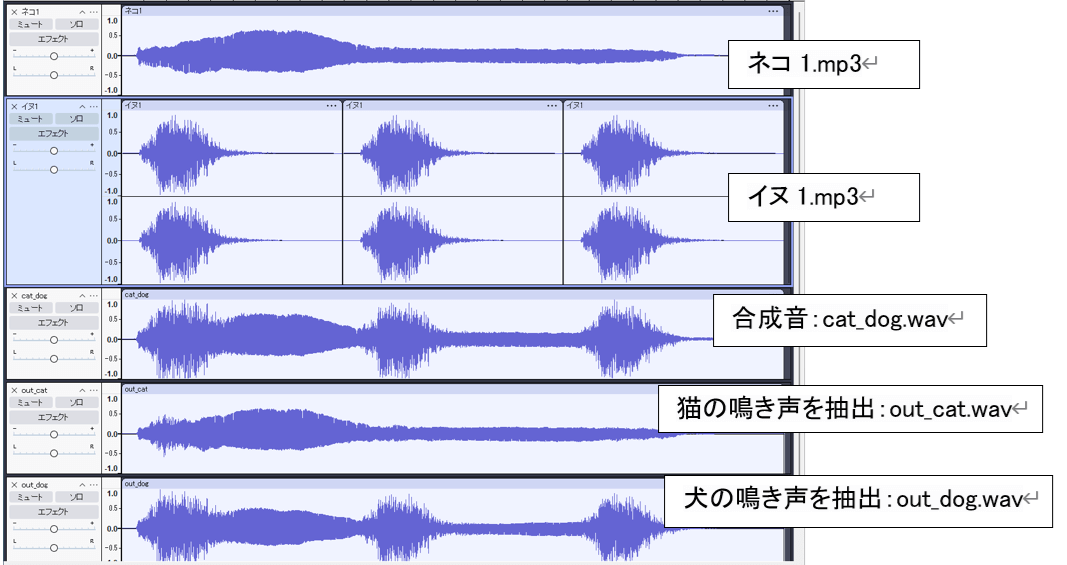
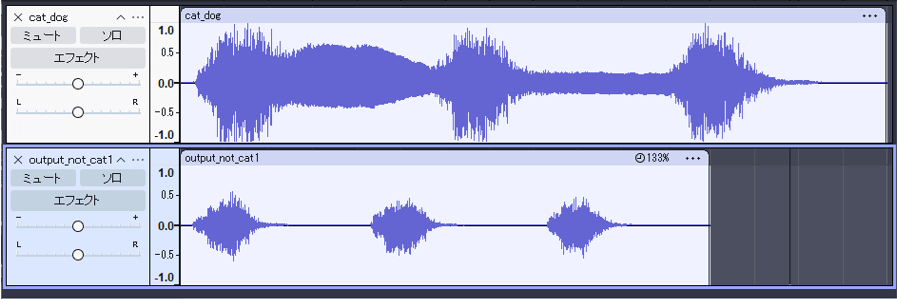
音源分離結果(図2)としては、自作した音源に対して、それぞれの動物名を自然言語クエリとして指定し、音の分離を試みました。
- catを指定した場合:猫の鳴き声が適切に抽出され、他の音は除去された。
- dogを指定した場合:出力された音声は入力音声とほぼ同じ内容で、分離が行われていないことを確認できた。
以上の結果から、今回使用したAudioSepモデルには犬の鳴き声に関する音響情報が学習されていない可能性が高いと推察されます。AudioSepは、自然言語によるプロンプトをもとに、該当する音声成分を抽出する仕組みですが、プロンプトに対応する音が学習時にモデルに登録されていない場合、音を抽出することができないという性質があります。
このように、抽出の成否はプロンプト内容とモデルが対応している音の種類に大きく依存する点に注意が必要です。
3、入力に含まれない音を指定した場合の確認
次に、猫と犬の鳴き声を含む音源に対して、全く関係のないプロンプトを指定した場合の挙動を確認します。ここでは、プロンプトとしてthunder(雷)を指定し、雷の音が存在しない音源に対する動作を検証します。
出力結果(図3)には、猫の鳴き声のごく一部が雷の音としてわずかに抽出されていました。ただし、その成分は非常に微弱であり、聴感上はほぼ無音に等しいレベルであったため、実質的には抽出されなかったとみなせる結果でした。
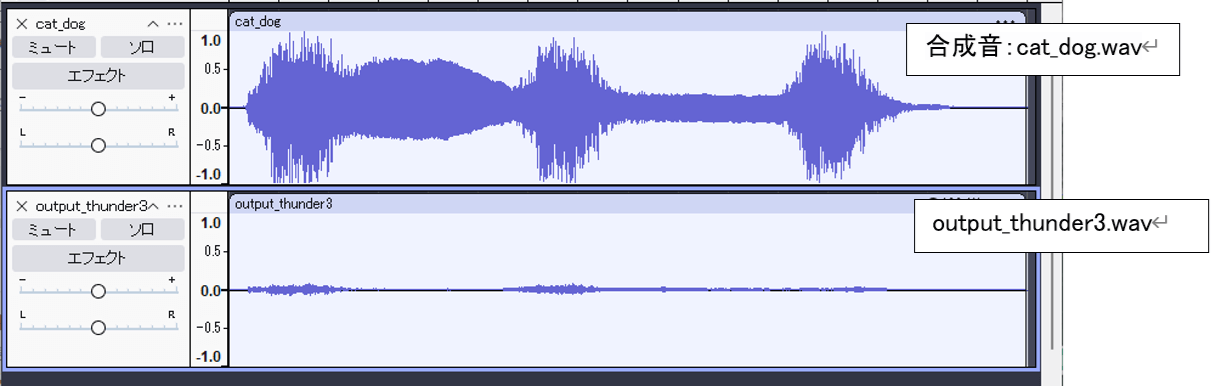
今回の検証結果から、入力音源に雷に相当する成分が存在しない場合、モデルは該当音を出力しないことが分かりました。
4、入力から削除する音を指定した場合の確認
2の結果から、今回使っているAudioSepのモデルには犬の鳴き声に関する情報が学習されていない可能性があると推察されました。そこで今回は、犬の鳴き声を抽出するのではなく、猫の鳴き声を削除するというアプローチで、残された音として犬の鳴き声のみを抽出できるかを確認します。使用したプロンプトはremove catです。
このプロンプトを指定して実行したところ、出力された音声から猫の鳴き声が除去され、犬の鳴き声のみが残されていることを音の再生によって確認できました。従って、削除対象の音を指定するという使い方も一応可能であることが示されました。一方で、Audacityによる波形表示では出力音声の再生速度や波形のタイミングにわずかな変化が生じていることが分かりました(図4)。
このことから、プロンプトの表現や入力音声の構成によっては削除処理が不安定になる可能性があると考えられます。今回のように、ある程度の除去効果が得られるケースもありますが、本来AudioSepは抽出したい音を指定する設計になっており、削除を目的とする場合にはプロンプトの書き方や入力音の構造に注意が必要です。
まとめ
今回は、自然言語による柔軟な音源分離を実現するAudioSepモデルをアイリアSDK上で動作させる手順と、その性能評価について解説しました。雷、水滴、猫、犬といった異なる種類の音を対象に、複数の検証を通じてAudioSepの特性を確認しました。
各検証から得られた知見を次に整理します。
- 登録済みの音であれば、高い精度で抽出可能。
- モデルに未登録の音に対しては、抽出が行われないか、入力と同等の出力となる。
- 無関係なプロンプト指定に対しては、不要な音の出力が抑制されている。
- 削除指示のプロンプトでも動作するが、安定性には課題もある。
今回紹介したAudioSepのチュートリアルは、アイリアSDKとPython環境があれば、誰でも手軽に再現可能です。興味を持たれた方は、ぜひご自身の音声素材でも試してみてください。
※記事に掲載している会社名、各製品名は、一般に各社の商標または登録商標です。
氏森 充(うじもり・たかし)氏
約30年間、株式会社構造計画研究所にてIoT、ビッグデータ、機械学習、AI関連のシステム開発や実務応用に従事。退職後はLLM(大規模言語モデル)関連の情報収集や技術動向の調査・発信に注力し、雑誌『Interface』でもLLM技術に関する記事を執筆中。

コンピューター・サイエンス&テクノロジ専門誌『Interface』
CQ出版社が発行するコンピュータ技術専門の月刊誌です。1974年の創刊以来、組み込みシステム、ソフトウェア、AI、IoTなど、時代とともに進化するコンピュータ技術を幅広く紹介しています。理論だけでなく、実践的なプログラミングや実機製作の記事も豊富で、エンジニアから学生まで、コンピュータ技術を深く学びたい読者に支持されています。
https://interface.cqpub.co.jp/
SHARE THIS ARTICLE












